[1506.02640v5] You Only Look Once: Unified, Real-Time Object Detection
没想到yolo竟然是2015年的技术。(U-Net也是同年的耶,甚至两个都是5月)
YOLO的作者是Joseph Redmon、Santosh Divvala、Ross Girshick、Ali Farhadi
Abstarct
Unified是说结构统一——一个网络就可以做到检测和分类。
YOLO很快,更快的速度换来的是更多的定位错误——但是很少定位到背景上。
有一定的开放性(比DPM和R-CNN更能表示图像)
Introduction
Current detection systems repurpose classifiers to per-
form detection. To detect an object, these systems take a
classifier for that object and evaluate it at various locations
and scales in a test image. Systems like deformable parts
models (DPM) use a sliding window approach where the
classifier is run at evenly spaced locations over the entire
image [10].
先前的目标检测有两种办法。一种是以滑动窗口在均匀间隔上分类来实现的DPM模型,另一种是以区域启发算法(region proposal method) 来实现的R-CNN。
YOLO采用了不同的思路:将目标检测任务看成回归问题,直接从图片像素上定位出边框和类别(而不是采用多个模型)。
Unified Detection
simultaneously adv.同时
妈耶,这么简单,我竟然看懂了。
YOLO的设计是支持端到端学习的,并且达到实时的同时还能获得高平均准确度。
YOLO的方法是这样的:
首先将输入图片切分成 网格。如果物体的中心落在网格内,则说物体是落在网格内的。
其次,对网格中每个单元格都预测个边框和这些边框的可信度(Confidence)。可信度反应了边框中是否有物体(注意和类型无关)以及边框是否和实际的标签的边框相符合。通常将可信度定义为。如果单元格没有物体,则可信度应该0。
每个边框可以用五个特征描述:还有可信度。代表框中心的坐标,代表框的宽度和高度。可信度代表预测框和实际标签框的IOU。
此外,每个单元格还预测了C个类别的概率(分类器)。这些概率都是基于单元格是否含有这个物体这一条件,而不是和上面预测的边框有关。
在测试时,将连续的某类类别概率乘上边框的可信度预测,可以得到:
Network Design
…
Training
We optimize for sum-squared error in the output of our
model. We use sum-squared error because it is easy to op-
timize, however it does not perfectly align with our goal of
maximizing average precision. It weights localization er-
ror equally with classification error which may not be ideal.
Also, in every image many grid cells do not contain any
object. This pushes the “confidence” scores of those cells
towards zero, often overpowering the gradient from cells
that do contain objects. This can lead to model instability,
causing training to diverge early on.
他们使用了sum-squared error(SSE)误差值,因为很好优化。但是他们认为优化SSE和他们追求的最大平均准确度有所差别,并且SSE将定位错误和分类错误看作是平等的,这可能会导致效果不够理想。此外如果图片中的单元格不包含物体,那会让单元格的可信度趋向0,时常导致总体的梯度倾向全都0而不是往有物体的方向靠。这样子会让模型不稳定,而且早早出现预测偏差。
remedy n.改进方法,补偿,改善措施 v.改进,补偿,纠正
因此他们增强了预测框坐标带来的损失,并减少了框内不包含物体带来的损失。他们使用了和参数来实现这个。在论文中他们设置这两个值为5。
同时SSE还将大边框和小边框的误差看成平等的了——实际上,大边框的小偏差损失应该比小边框的小偏差小。为此,他们预测的是边框的宽度、高度的平方根,而不是直接预测宽高。
YOLO predicts multiple bounding boxes per grid cell.
At training time we only want one bounding box predictor
to be responsible for each object. We assign one predictor
to be “responsible” for predicting an object based on which
prediction has the highest current IOU with the ground
truth. This leads to specialization between the bounding box
predictors. Each predictor gets better at predicting certain
sizes, aspect ratios, or classes of object, improving overall
recall.
这段我大脑要看烧了……
虽然YOLO在每个单元格都会预测多个框,但是YOLO只会将与真实物体框IOU最高的那个框参与进损失的计算中。因此这些框能够不尽相同、各具特色(也就是原文说的specialization 专业化),不同的框各自擅长检测不同的的物体。
损失函数懒得写了,直接看图吧:
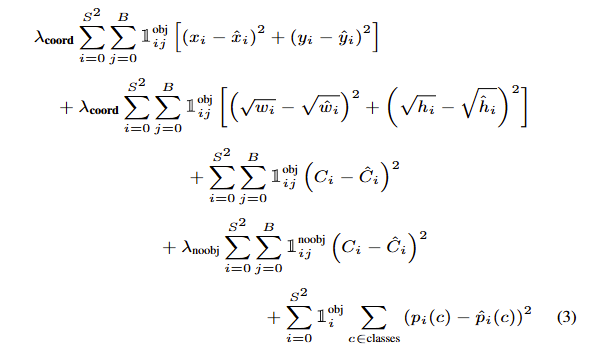
注意两点:第一点是只有在分类正确的时候才会算上分类错误的损失;第二点是只有在判定有物体在单元格内的时候才判定框框预测偏差的损失。
训练过程自己看:
Our learning rate schedule is as follows: For the first
epochs we slowly raise the learning rate from 10−3 to 10−2.
If we start at a high learning rate our model often diverges
due to unstable gradients. We continue training with 10−2
for 75 epochs, then 10−3 for 30 epochs, and finally 10−4
for 30 epochs.
To avoid overfitting we use dropout and extensive data
augmentation. A dropout layer with rate = .5 after the first
connected layer prevents co-adaptation between layers [18].
For data augmentation we introduce random scaling and
translations of up to 20% of the original image size. We
also randomly adjust the exposure and saturation of the im-
age by up to a factor of 1.5 in the HSV color space.
Inference
Just like in training, predicting detections for a test image
only requires one network evaluation.
(作者的反复强调)
spatial adj.空间的
Often it is clear which grid cell an
object falls in to and the network only predicts one box for
each object. However, some large objects or objects near
the border of multiple cells can be well localized by multi-
ple cells. Non-maximal suppression can be used to fix these
multiple detections.
笑似,终于提到了这个问题。
通常将一个单元格预测一个框框住一个物体,但是有时候一些超大型的物体占了好几个单元格,这个时候怎么办呢?——作者使用了非最大化抑制(Non-maximal suppression)。
然后又拌了R-CNN和DPM一下www
While not critical to performance as it
is for R-CNN or DPM, non-maximal suppression adds 2-
3% in mAP.
Limitations of YOLO
又幻想了,幻想 YOLO 无人能挡,完美无瑕。
YOLO对空间有相当强的约束——规定了一个单元格只预测两个边界框和一个类。因此在遇到小物体扎堆的时候就炸了——比如说鸟群。
Since our model learns to predict bounding boxes from
data, it struggles to generalize to objects in new or unusual
aspect ratios or configurations. Our model also uses rela-
tively coarse features for predicting bounding boxes since
our architecture has multiple downsampling layers from the
input image.
因为模型是从边界框中学习数据的,所以对于那些非常规的物体比例表现不好。此外因为使用了降采样来学习,学到的特征也是粗略的特征,也会表现不好。(TODO: 这段读起来有点蒙圈)
Conclusion
结构简单。可以直接在整张图上训练。检测和分类直接在一个损失函数上训练。Fast YOLO很快,模型推广性很好。